
(Guest Post by Matthew Ladner)
Matthew DiCarlo of the Shanker Institute has taken to reviewing the statistical evidence on the Florida K-12 reforms. DiCarlo reaches the conclusion that we ultimately can’t draw much in the way of conclusions regarding aggregate movement of scores. He’s rather emphatic on the point:
In the meantime, regardless of one’s opinion on whether the “Florida formula” is a success and/or should be exported to other states, the assertion that the reforms are responsible for the state’s increases in NAEP scores and FCAT proficiency rates during the late 1990s and 2000s not only violates basic principles of policy analysis, but it is also, at best, implausible. The reforms’ estimated effects, if any, tend to be quite small, and most of them are, by design, targeted at subgroups (e.g., the “lowest-performing” students and schools). Thus, even large impacts are no guarantee to show up at the aggregate statewide level (see the papers and reviews in the first footnote for more discussion).
DiCarlo obviously has formal training in the statistical dark arts, and the vast majority of academics involved in policy analysis would probably agree with his point of view. What he lacks however is an appreciation of the limitations of social science.
Social scientists are quite rightly obsessed with issues of causality. Statistical training quickly reveals to the student that people are constantly making ad-hoc theories about some X resulting in some Y without much proof. Life abounds with half-baked models of reality and incomplete understandings of phenomena, which have a consistent and nasty habit of proving quite complex.
Social scientists have developed powerful statistical methods to attempt to establish causality techniques like random assignment and regression discontinuity can illuminate issues of causality. These types of studies can bring great value, but it is important to understand their limitations.
DiCarlo for instance reviews the literature on the impact of school choice in Florida. Random assignment school choice studies have consistently found modest but statistically significant test score gains for participating students. Some react to these studies with a bored “meh.” DiCarlo helps himself along in reaching this conclusion by citing some non-random assignment studies. More problematically, he fails to understand the limitations of even the best studies.
For example, even the very best random assignment school choice studies fall apart after a few short years. Students don’t live in social science laboratories but rather in the real world. Random lotteries can divide students into nearly identical groups with the main difference being that one group applied for but did not get to attend a charter or private school. They cannot however stop students in the control group from moving around.
Despite the best efforts of researchers, attrition immediately begins to degrade control groups in random assignment studies. Usually after three years, they are spent. Those seeking a definitive answer on the long-term impact of school choice on student test scores are in for disappointment. Social science has very real limits, and in this case, is only suggestive. Choice students tend to make small but cumulative gains year by year which tend to become statistically significant around year three, which is right around when the random assignment design falls apart. What’s the long-term impact? I’d like to know too, but it is beyond the power of social science to tell us, leading us to look for evidence from persistence rates.
So let’s get back to DiCarlo, who wrote “The reforms’ estimated effects, if any, tend to be quite small, and most of them are, by design, targeted at subgroups (e.g., the “lowest-performing” students and schools). Thus, even large impacts are no guarantee to show up at the aggregate statewide level.” This is true but fails to recognize the poverty of the social science approach itself.
DiCarlo mentions that “even large impacts are no guarantee to show up at the aggregate statewide level.” This is a reference to the “ecological fallacy” which teaches us to employ extreme caution when travelling between the level of individual and aggregate level data. Read the above link if you want to know all the brutally geeky reasons why this is the case, take my word for it if you don’t.
DiCarlo is correct that connecting the individual level data (e.g. the studies he cites) to aggregate level gains is a dicey business. He however fails to appreciate the limitations of the studies he cites and the fact that the ecological fallacy problem cuts both ways. In other words, while generally positive, we simply don’t know the relationship between individual policies and aggregate gains.
We know for instance that we have a positive study on alternative certification and student learning gains. We do not and essentially cannot know however how many if any NAEP point gains resulted from this policy. The proper reaction for a practical person interested in larger student learning gains should be summarized as “who cares?” The evidence we have indicates that the students who had alternatively certified teacher made larger learning gains. Given the lack of any positive evidence associated with teacher certification, that’s going to be enough for most fair minded people.

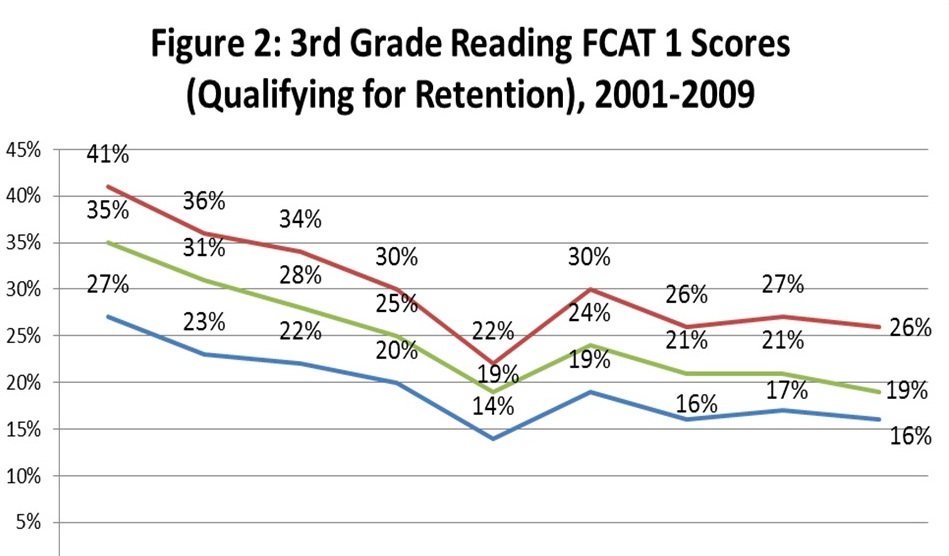
The individual impact of particular policies on gains in Florida is not clear. What is crystal clear however is the fact that there were aggregate level gains in Florida. You don’t require a random assignment study or a regression equation, for instance when considering the percentage of FCAT 1 reading scores (aka illiterate) above. When you see the percentage of African American students scoring at the lowest of five achievement levels drop from 41% to 26% on a test with consistent standards, it is little wonder why policymakers around the country have emulated the policy, despite DiCarlo’s skepticism.
I could go on and bomb you with charts showing improving graduation rates, NAEP scores, Advance Placement passing rates, etc. but I’ll spare you. The point is that there are very clear signs of aggregate level improvement in Florida, and also a large number of studies at the individual level showing positive results from individual policies.
The individual level results do not “prove” that the reforms caused the aggregate level gains. DiCarlo’s problem is that they also certainly do not prove that they didn’t. It has therefore been necessary from the beginning to examine other possible explanations for the aggregate gains. The problem here for skeptics is that the evidence weighs very much against them: Florida’s K-12 population became both demographically and economically more challenging since the advent of reform, spending increases were the lowest in the country since the early 1990s (see Figure 4) and other policies favored by skeptics come into play long after the improvement in scores began.
The problem for Florida reform skeptics, in short, is that there simply isn’t any other plausible explanation for Florida’s gains outside of the reforms. They flailed around with an unsophisticated story about 3rd grade retention and NAEP, unable and unwilling to attempt to explain the 3rd grade improvement shown above among other problems. One of NEPC’s crew once theorized that Harry Potter books may have caused Florida’s academic gains at a public forum. DiCarlo has moved on to trying to split hairs with a literature review.
With large aggregate gains and plenty of positive research, the reasonable course is not to avoid doing any of the Florida reforms, but rather to do all of them. In the immortal words of Freud, sometimes a cigar really is just a cigar.




 Posted by Jay P. Greene
Posted by Jay P. Greene 





 (Guest Post by Matthew Ladner)
(Guest Post by Matthew Ladner) (Guest Post by Matthew Ladner)
(Guest Post by Matthew Ladner)
